一、什么是插桩
程序插桩(Instrumentation)是一种软件工程技术,它涉及在不改变程序原有逻辑的前提下,向程序代码中添加额外的代码片段,这些额外的代码的主要目的是收集程序运行时的详细信息,以便于分析、测试、调试或性能监控。
把程序本身比作一位做菜的厨师,插桩类似于该厨师的学徒或助手,师父做菜的时候,在不影响师父做菜的流程的情况下,在某些点记录做菜流程的数据,比如用了多少调料,烹饪的时间等。
二、为什么需要插桩
插桩是监控程序行为的一种工具,通过插桩技术可以更好地对程序的行为进行监控分析。
对于程序优化来说,插桩技术可以辅助分析代码覆盖率、热点代码片段,甚至发现内存泄漏等安全漏洞,是一种非常有效的辅助手段。
此外,插桩技术还可以进行性能分析、安全审计、程序质量评估等工作。
三、插桩的分类
- 手动(Manual):是由程序设计者加入指令,在执行时计算相关信息。
- 源代码层级自动处理(Automatic source level):依照插桩政策,利用自动化工具自动在源代码中加入插桩。
- 中间语言(Intermediate language):在汇编语言或是字节码(Bytecode)中加入针对多种高级语言的插桩,要避免无符号二进制偏移重写问题。
- 编译器协助(Compiler assisted):像gprof和Quantify都是这类的例子,像用*gcc -pg …可以使用gprof,用quantify g++ …*可以使用Quantify。
- 二进制翻译(Binary translation):此工具在编译好的可执行程序(executable)中加入插桩。
- 执行时插桩(Runtime instrumentation):代码直接在执行前修改,工具可以完成的监控及控制程序的执行。
- 执行时注入(Runtime injection):修改程度比执行时插桩要小,在运行时修改代码,以便跳转到注入的代码入口。
其中
Manual、Automatic source level、Intermediate language、Compiler assisted属于静态插桩
静态插桩是指在源代码编译成为可执行程序期间一并进行编译的插桩。然而,静态插桩也包括指令级别的插桩,即在某条机器指令的前后进行插桩。这样的实现可以通过编译器插件对编译器进行扩展,从而在编译过程中的某个阶段介入对中间表示(IR)进行修改,或者说在编译过程中的生成汇编代码(Compilation)后、链接(Linking)之前对汇编代码进行修改。(Preprocessing -> Compilation -> Assembly -> Linking)
Runtime instrumentation、Runtime injection属于动态插桩
动态插桩指的是在程序运行时进行的插桩。
Binary translation包含动态二进制翻译和静态二进制翻译,分别属于静态插桩和动态插桩
根据插桩的级别,插桩可以分为源代码级别的插桩和二进制代码级别的插桩。然而,现有的插桩工具,如Intel Pin,实际上提供了更多级别的插桩,如Basic Block级别的插桩。
1 | ⭐提出问题: |
静态插桩和动态插桩的对比
| 静态插桩 | 动态插桩 |
|---|---|
| 程序运行之前插桩 | 程序运行时插桩 |
| 无法实时更改、适应 | 可以根据程序行为即时调整策略 |
1 | 心得20240501: |
四、DynamoRIO
概念
一个运行时代码操作系统。随着软件技术的发展,静态优化手段不太能跟上对软件中频繁出现的诸如DDL、共享库、运行时绑定等新技术的使用,把优化推迟到程序运行时可以解决这些问题,DynamoRIO因此而生。而动态插桩是实现动态优化的基础手段。
DynamoRIO的论文写于2002年。
架构设计
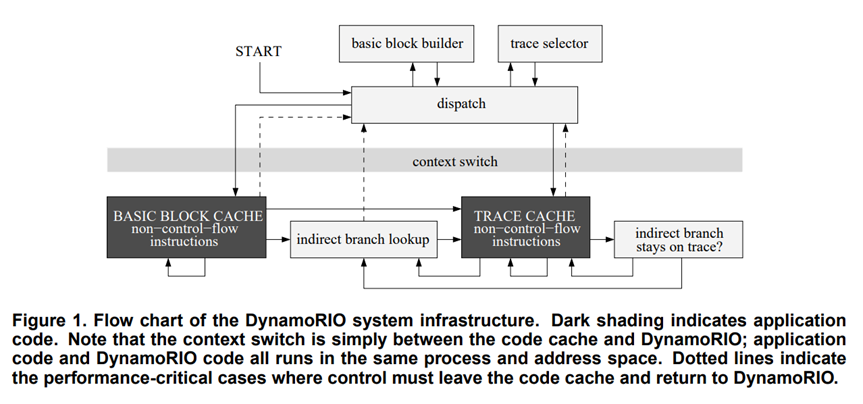
在开始运作时,内存空间中由DynamoRIO的指令开始执行,找到目标应用程序的指令的地址,通过Basic Block Builder对该指令进行切分,并把之前的不包含跳转或返回指令的片段划分为一个基本块,复制到Code Cache中。
基本块(Basic Block)指一段指令序列,该序列中有且仅有最后一个指令是跳转或返回指令,在其之前的所有指令都必然是顺序执行的无分支指令。
在每个跳转或返回指令的位置作为最后一条指令进行切分,可以方便地理清控制流。
通过Context Switch把控制权交给应用程序。Context Switch是一个交换控制权的机制,它主要做的事有暂存程序运行状态,如寄存器的值。
Our context switch to and from the fragment cache are arranged such that there is no persistent state kept on the dstack, allowing us to start with a clean slate on exiting the cache. This eliminates the need to protect our dstack from inadvertent or malicious writes. We do not bother to save any DynamoRIO state, even the eflags.
实际上 Context Switch 并不会保存DynamoRIO的状态,以防止恶意或无意写入。
1 | ⭐提出问题: |
执行Basic Block Cache中的指令,如果最后一句指令是直接跳转,即只有一种情况的单分支跳转,且跳转的地址已经在Basic Block Cache中了,那么就直接继续执行,否则通过Context Switch存储当前应用程序的状态并切换到DynamoRIO中执行指令复制的操作。
如果Basic Block Cache中最后的跳转语句是多分支的,即跳转的地址可能有多个的,就使用一个Hash table来查找地址映射,这个过程称为间接分支查找。这个Hash table的建立时,是以目标程序的内存地址为键,Code Cache中的地址为值的。
间接分支查找的过程中,如果有经常按照某个特定分支继续执行时,会把下一个基本块和现在执行的代码块直接连接在一起,称为Trace。在一个基本块完成时仍然会由最后一个跳转或返回指令进行寻址,如果符合Trace Cache,就留在Trace Cache中继续执行,否则再进行完整的查找。
这种设计带来的性能提升可以在很大程度上弥补建立这种结构带来的开销,且通常优于原程序的速度。
DynamoRIO Client
指令的表示级别
指Code Cache中程序的指令的详细程度
Level 0,直接保存指令序列,不进行任何拆分
Level 1,拆分了每一条指令
Level 2,增记了每条指令对应的操作(opcode)以及eflags
Level 3,增记操作数(operands)
Level 4,对指令进行了重新编码以适应优化或重组需求
一个Basic Block中缓存的指令可以包含不同的指令级别。比如,只有最后一条指令是跳转或返回指令,则只对最后一条指令应用level 3指令级别,之前的指令仅保存指令序列,即level 0指令级别。
DynamoRIO提供了一个叫做InstrList的数据结构,简单来理解就是一个List里面有多个Instr,而Instr存储机器码序列。
API
DynamoRIO 程序本体运行时会在每个线程的私有内存空间中创建多个 API(例程),并在 thread-local slots 来存储寄存器的值。此外,它还提供了一个共享的空间供其他 DynamoRIO 运行的线程使用,并在 Instr 数据结构中提供了一个用于注释的字段。
Basic Block或Trace在运行结束时,DynamoRIO提供了一个叫做custom exit stubs的机制,用于在Context Switch之前保存退出的位置,且在每个stub中可以附加一些指令或代码,以此来实现插桩。
API中还包含一些识别处理器的功能用于执行特定体系下的优化。
thread-local slots : 线程私有槽,用于在本线程中保存一些数据,在DynamoRIO中主要是寄存器的值。
在源代码的
core/fcache.c中定义了代码缓存的核心逻辑,其实就是在线程所独占的内存中开放的一个可以存储数据的空间。此处问题:这是不是DynamoRIO的一个特殊机制?在别的多线程程序中,应该也有类似的机制来避免多个线程争抢register。
custom exit stubs:该Stub给了插桩可能性。此处对应源代码中
core/fragment.h中定义的struct _fragment_t数据结构,此结构是basic block和trace的数据结构。使用FRAGMENT_EXIT_STUBS()访问
Client
Client可以实现一些常用功能

这里的*context是一个不应被修改的参数,是一个指向当前线程的context的指针。tag是用于根据被插桩程序唯一标识fragment
Client还提供了自适应优化的接口,即
1 | InstrList* dr_decode_fragment(void *context, app_pc tag); |
这两个接口的作用是对已经缓存的Trace进行修改,该修改是热插拔的。
还有一个接口是自定义Trace头的
1 | void dr_mark_trace_head(void *context, app_pc tag); |
实践-基本块的平均大小(官方示例添加注释)
在DynamoRIO Client的测试中,有一种在用调试器去调试调试器的感觉。
main函数
1
2
3
DR_EXPORT void dr_client_main(client_id_t id, int argc, const char *argv[]) {}注册callback function,callback function是一个“让API调用我自己”的函数,用作DynamoRIO调用Client中自己实现的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14//声明
static void event_exit(void);
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb,bool for_trace, bool translating);
//注册
DR_EXPORT void dr_client_main(client_id_t id, int argc, const char *argv[])
{
// 注册退出函数
dr_register_exit_event(event_exit);
// 注册 basic block 级别的回调函数,这里用作添加插桩代码
dr_register_bb_event(event_basic_block);
}
//实现todo实现回调函数,以下是全部代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
// 基本块计数、指令计数
typedef struct bb_counts {
uint64 blocks;
uint64 total_size;
} bb_counts;
// 全局变量,用作计数
static bb_counts counts_as_built;
// 全局变量,锁
void *as_built_lock;
// 进程退出回调函数
static void event_exit(void);
// 基本块回调函数
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb,bool for_trace, bool translating);
// DynamoRIO Client的 main 函数
DR_EXPORT void dr_client_main(client_id_t id, int argc, const char *argv[])
{
// 注册退出函数
dr_register_exit_event(event_exit);
// 注册 basic block 级别的回调函数,这里用作添加插桩代码
dr_register_bb_event(event_basic_block);
// 创建锁
as_built_lock = dr_mutex_create();
}
// 在运行结束时显示结果
static void event_exit(void) {
char msg[512];
int len;
len = snprintf(msg, sizeof(msg) / sizeof(msg[0]),
"Number of basic blocks built : %"UINT64_FORMAT_CODE"\n"
" Average size : %5.2lf instructions\n",
counts_as_built.blocks,
counts_as_built.total_size / (double)counts_as_built.blocks);
DR_ASSERT(len > 0);
msg[sizeof(msg)/sizeof(msg[0])-1] = '\0';
DISPLAY_STRING(msg);
// 解除锁
dr_mutex_destroy(as_built_lock);
}
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb, bool for_trace, bool translating) {
uint num_instructions = 0;
instr_t *instr;
// instrList用于存储指令,每个instr都是一部分指令,这里可以计数指令的数量
for (instr = instrlist_first(bb); instr != NULL; instr = instr_get_next(instr)) {
num_instructions++;
}
dr_mutex_lock(as_built_lock);
// 在自定义的结构中自增,用以基本块计数
counts_as_built.blocks++;
counts_as_built.total_size += num_instructions;
dr_mutex_unlock(as_built_lock);
return DR_EMIT_DEFAULT;
}
实践-自写递归函数调用栈深
自写部分使用drmgr
测试用程序,本程序是一个求解数独的算法,使用了回溯法,使用DynamoRIO Client插桩的目的是查看递归的函数调用的深度
1 | /* |
1 | ⭐提出问题: |
CMakeLists.txt1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29cmake_minimum_required(VERSION 3.10)
project(myclient)
# 设置DynamoRIO的安装路径
# set(DynamoRIO_DIR D:/Tools/DynamoRIO-10.0.0/cmake)
set(DynamoRIO_DIR /root/app/dynamorio/cmake)
add_library(myclient SHARED myclient.c)
# 查找DynamoRIO的包
find_package(DynamoRIO REQUIRED)
# 包含DynamoRIO的头文件
include_directories(${DynamoRIO_INCLUDE_DIRS})
# 设置项目源文件
set(SOURCES myclient.c)
# 生成可执行文件
#add_executable(myclient ${SOURCES})
# 链接DynamoRIO的库文件
target_link_libraries(myclient ${DynamoRIO_LIBRARIES})
use_DynamoRIO_extension(myclient drmgr)
use_DynamoRIO_extension(myclient drwrap)
configure_DynamoRIO_client(myclient)myclient.cDynamoRIO使用形如
dr_insert_call_instrumentation之类的方法来实现使用回调函数插桩,诸如此类的函数还有dr_insert_mbr_instrumentation``dr_insert_cbr_instrumentation,在它们内部都调用了dr_insert_clean_call,这个函数需要传入当前分支指令的地址和目标分支指令的地址1
2
3
4
5
6
7
8
9// 这里是源码,用于讲解,不是我的Client。
// 这个Clean call其实是为了实现Transparency
// 在这个函数中可以切换到 clean 的内存堆栈,并选择性地保存寄存器
void dr_insert_clean_call_ex_varg(void *drcontext, instrlist_t *ilist, instr_t *where,
void *callee, dr_cleancall_save_t save_flags, uint num_args,
opnd_t *args)
{
// [...] 这里有一堆看着头大的汇编代码,我决定暂时放弃研究它
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
int recursion_depth = 0;
int max_recursion_depth = 0;
// 插桩函数 - 在进入递归函数时增加递归深度
void enter_recursive_function(void *drcontext, void **tag) {
recursion_depth++;
dr_printf("当前调用深度为 %d" "\n", recursion_depth);
if (max_recursion_depth < recursion_depth) {
max_recursion_depth = recursion_depth;
dr_printf("当前最大调用深度为 %d" "\n", max_recursion_depth);
}
}
// 插桩函数 - 在离开递归函数时减少递归深度
void exit_recursive_function(void *drcontext, void *tag) {
recursion_depth--;
dr_printf("当前调用深度为 %d" "\n", recursion_depth);
}
static void module_load_event(void *drcontext, const module_data_t *mod, bool loaded)
{
// 返回给定函数的入口点
app_pc towrap = (app_pc)dr_get_proc_address(mod->handle, "_Z3sskRSt6vectorIS_IcSaIcEESaIS1_EE");
// dr_printf("come in 入口点 _Z3sskRSt6vectorIS_IcSaIcEESaIS1_EE " PFX " \n", towrap);
if (towrap != NULL) {
// 在函数执行前插桩
bool ok = drwrap_wrap(towrap, enter_recursive_function, exit_recursive_function);
if (!ok) {
DR_ASSERT(ok);
}
}
}
static void event_exit(void)
{
dr_printf("最大调用深度为 %d" "\n", max_recursion_depth);
drwrap_exit();
drmgr_exit();
}
DR_EXPORT void dr_init(client_id_t id)
{
drmgr_init();
drwrap_init();
dr_register_exit_event(event_exit);
drmgr_register_module_load_event(module_load_event);
}在Windows下,直接
cmake ..是不可以的,要用cmake .. -G "Unix Makefiles"才会生成熟悉的带有Makefile输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19测试shell
准备一个cpp,这里是随便找的一个计算数独的算法
进入写了上面的文件的文件夹,把cpp文件放进去
cd ~/code/dynamorio_client
mkdir build
cd build
编译,要拿到符号
g++ -rdynamic 00920037.cpp -o targ
nm -D targ | grep ssk
编译
cmake ..
make
运行 要先设置好DYNAMORIO_HOME或者给一个路径
drrun -debug -root $DYNAMORIO_HOME -c ./libmyclient.so -- ./targ
要了老命了搞了得有10个小时
结果

1 | 心得20240504: |
五、Intel Pin
概念
Pin 是一个由 Intel 开发的非开源动态二进制插桩工具软件,只支持Intel平台。
Pin 首个版本发布于2004年7月,论文发布于2005年。
架构设计
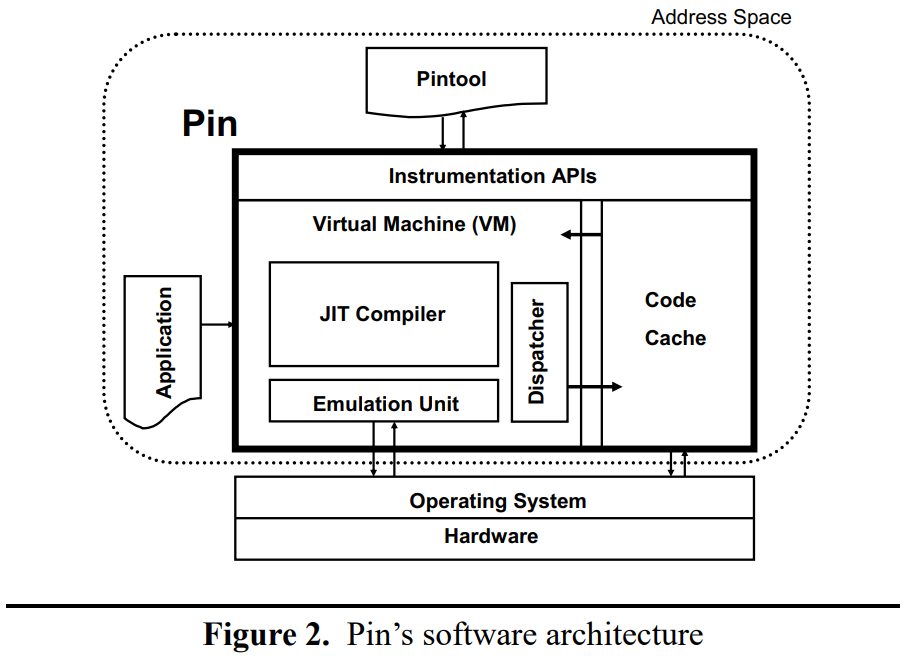
- Pintool 通过 Instrumentation API 调用虚拟机
- JIT即时编译目标程序(此时可以插桩),且通常是从一个ISA翻译到相同的ISA,编译后的代码通过Dispatcher存储在Code Cache中。
- 由Dispacher启动目标程序。Code Cache和VM之间涉及到保存和恢复应用程序的寄存器状态(Context Switch)
- Emulation Unit的主要作用是针对不同的运行环境(操作系统、指令集)来以不同的策略对代码进行编译,以一个虚拟机或Docker的角度来理解即可。
1 | ⭐提出问题: |
- Code Cache存储了目标程序的指令以及可能存在的插桩指令。
- 总结一下,PIN是一个引擎,负责即时编译、插桩Application;Application是待分析的目标应用程序;Pintool是通过Instrumentation API来实现的自定义插桩规则。这三个不同的部分会采用直接保存三份glibc的方式来避免发生代码重入的冲突。
数据流转
PIN通过
UNIX ptrace API来注入目标应用程序中,该方式可以把PIN的二进制文件寄生到目标应用程序上去DynamoRIO使用的是
LD PRELOAD,PIN的改进点在于,LD PRELOAD不处理静态连接、加载额外的共享库可能会把这些共享库的内存地址堆得很高、LD PRELOAD需要加载一部分之后才能执行插桩程序而PIN在第一条指令就可以插桩(PIN作者认为这是一个LD PRELOAD的bug)PIN把Pintool加载到内存中并启动,Pintool加载完成后要求PIN启动Application
PIN开始通过JIT编译目标应用程序,Application的原始代码不会被执行,一般情况下,PIN直接从一个ISA编译到同一个ISA。
PIN编译应用程序时按照代码块来分步执行,遇到以下三种情况之一的就会暂停编译
- 无分支跳转
- 有分支跳转
- 代码缓存中已经有了该路径的建立
如果有代码块的执行路径经常被执行,则链接它们成为
Trace。基本思路和DynamoRIO是一致的,显然借鉴了DynamoRIO的思路。但在很多细节处有不同,因为PIN是后来者,所以进行了一些改进。
在Trace的建立过程中,DynamoRIO是在Translation的过程中一次性建立好,所以不能在Trace中添加新的预测轨迹。而PIN可以在Trace的链中把新的基本块添加进来。所以,DynamoRIO在Trace未命中时选择通过Indirect branch lookup搜索哈希表,而PIN可以在该Trace中再搜索。
DynamoRIO在Indirect branch lookup中使用的是global hash table,而PIN使用了local hash table。这里的local指的是,每一个Indirect branch lookup,而不是线程本地。
对于某些经常被调用的函数,在内存中创建多个副本,这样每个副本就可以成为某个Trace的专属调用链路的一部分,从而减少间接跳转。
这里我认为这样的方式不是在任何情况下都是有效的。
如果代码块已经执行结束,则有可能出现间接跳转,并需要通过PIN重新编译新的代码块到Code Cache中。
这里就涉及到了寄存器暂存的问题。这里也是PIN相对于DynamoRIO的不同点。
寄存器重分配:在JIT中经常需要额外的寄存器,Pintool和Application需要占用的寄存器经常发生冲突,尤其JIT编译(翻译)包含插桩的代码时。PIN使用了
Linear-scan register allocation这个寄存器重分配算法,指的是通过一次遍历,来确定每个变量需要多少个寄存器,并且把寄存器分配给变量。PIN还支持跨函数的寄存器分配。这里也涉及到寄存器状态分析,PIN可以在不溢出(Spilling)寄存器的情况下使用dead register。寄存器重分配在DynamoRIO中是没有的,根据看到的代码,DynamoRIO在Context Switch时,会把所有的寄存器的值都写入thread-local slots中。
寄存器溢出(Register spilling):此部分和DynamoRIO类似。PIN把某个物理寄存器用作存放指向某个线程的虚拟寄存器的指针,因为线程的虚拟寄存器必须是thread-local的,所以物理寄存器的指针用作动态存储当前线程的虚拟寄存器位置。
Pintool
插桩级别
INS_AddInstrumentFunction指令级插桩TRACE_AddInstrumentFunctionTrace插桩,实际上也是基本块插桩IMG_AddInstrumentFunction镜像插桩,需要提前PIN_InitSymbols()1
2
3
4
5
6
7
8
9⭐提出问题:
不是很懂什么叫IMG,API doc中的解释是
An IMG represents all the data structures corresponding to a binary (executable).
https://software.intel.com/sites/landingpage/pintool/docs/98830/Pin/doc/html/group__IMG.html
查阅了一番资料之后没有更加详细的解释,目前我自己的理解是,IMG是代表了一个二进制的可执行文件本身。IMG级别的插桩的意思是,在一个给定的二进制可执行文件中,通过`PIN_InitSymbols()`能找到的符号代表的位置都可以插桩,比如数据结构、函数、变量。
但是我不敢确定我的理解是不是正确。
解决思路:
问老师。RTN_AddInstrumentFunction例程插桩(函数级插桩),需要提前PIN_InitSymbols()
代码模型
直接上例子比较直观
1 |
|
六、DynamoRIO vs Pin
DynamoRIO是一个开源的,以优化为主要目的,以插桩为基本手段的系统优化工具,由来自MIT、VMWare的团队开发。
Pin是一个闭源的,仅支持Intel平台的免费插桩工具。
在PIN的测试中,在不插桩的情况下,DynamoRIO的统计基本块速度比PIN快12%。由于PIN寄存器重分配、动态Trace建立、local hash table、重用函数副本的机制下,在插桩代码的效率对比上,PIN比DynamoRIO快了很多。
When we consider the performance with instrumentation shown in Figure 7(b), Pin outperforms both DynamoRIO and Valgrind by a significant margin: on average, Valgrind slows the application down by 8.3 times, DynamoRIO by 5.1 times, and Pin by 2.5 times.
1 | 心得20240512 |