Overview
指令(instruction)的执行依托于计算机体系结构的通力合作。在第1节先介绍指令是如何在计算机体系结构下运行的。第2节对汇编进行简单介绍。第3节对汇编、链接、加载的工具链进行介绍。
这些知识是为了对现代程序的执行过程有一个更加底层的理解,且由于这些知识对细节的要求比较高,所以能对系统优化有更清晰的认识。
1. 计算机体系结构
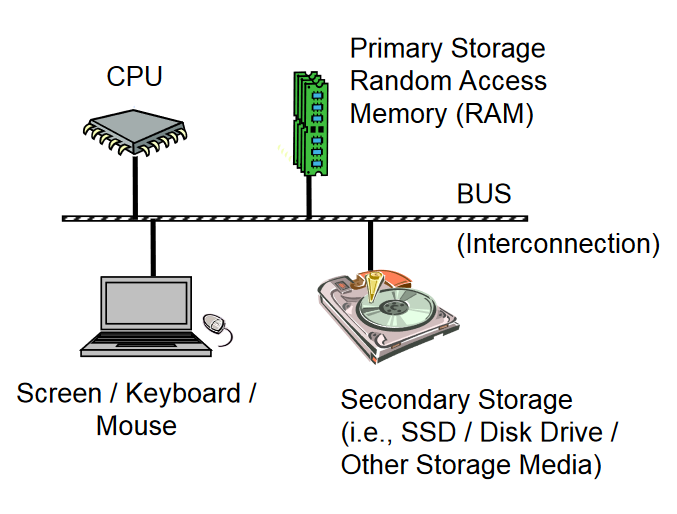
现代计算机中包含的主要组件如图,CPU是计算的核心,RAM为**主存(Primary Storage)**,
我们熟知的固态硬盘、机械硬盘等为**二级存储(Secondary Storage)**。
CPU内部又包含多级**缓存(Cache Memory)**和寄存器(Register)。
这些看起来略显复杂的架构其实只是为了让CPU更快地处理数据,本质上来说,以上所述元件都是把数据的流转速度进行多次加速给CPU进行处理。
1.1 数据存储方式(X86_64)
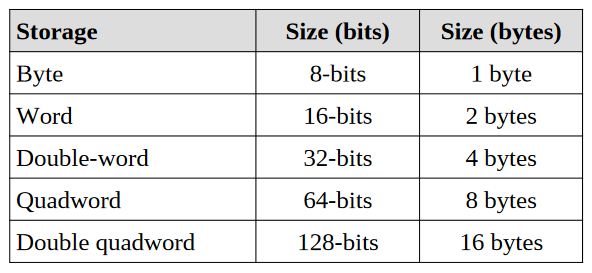
不同指令集架构(ISA,Instruction-Set Architecture)中数据存储的方式是不同的,在X86_64架构中,数据按照以下大小进行存储:
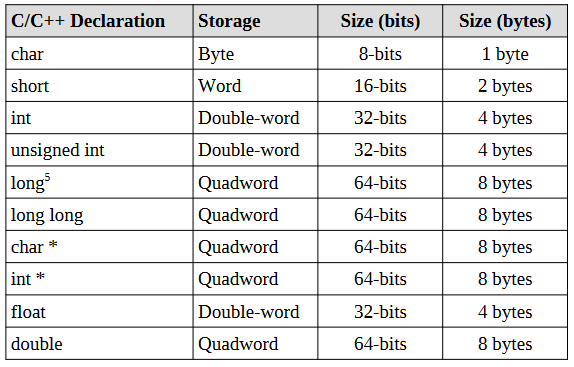
不同的语言中又使用了各自封装的存储类型,但底层存储依然是以上几种存储方式。例如,在C/C++中:
1.2 CPU
CPU(Central Process Unit),直接翻译为核心处理装置,我们通常翻译为中央处理器,是计算机体系结构的核心,它负责处理一条条指令。
寄存器(Register)与缓存(Cache Memory)是CPU的组成部分。
在对指令学习的过程中,对寄存器的理解是前置知识中最重要的部分。
1.2.1 寄存器
寄存器是CPU临时存放与处理数据的位置。
1 | ⭐提出问题: |
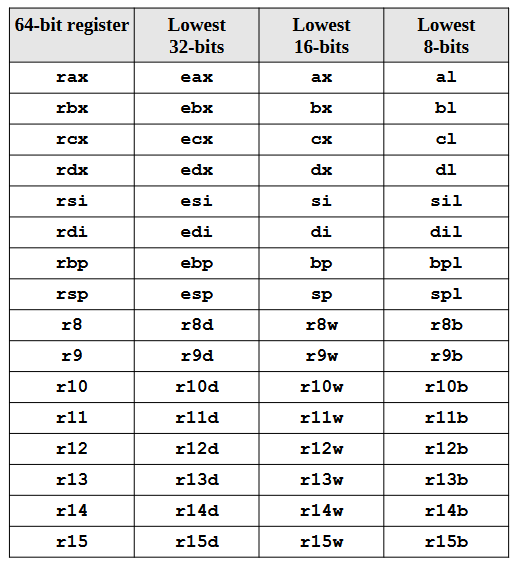
在使用X86_64指令集的CPU中,有以下几种主要的**通用寄存器(GPRs, General Purpose Registers)**:
Processor register - Wikipedia
其中rax/rbx/rcx/rdx允许低位部分直接作为单独的寄存器存放数据:

这其中的一些寄存器的作用如下:
RSP堆栈寄存器、RBP基本指针寄存器、RIP指令指针寄存器。这些寄存器都是64位的。
此外XMM寄存器是一个128bit的寄存器,主要用于支持浮点运算和SMID(Single Instruction Multiple Data),关于SMID这里不做详细展开。该寄存器推出于SSE指令集。后来Intel推出AVX/AVX2等指令集中,引入了256bit的YMM寄存器作为XMM的扩展,并与XMM兼容。
此处仅对寄存器有一个大概的概念即可,深入学习需要投入专门的时间与精力。我把它放入下一个阶段进行学习。
1.2.2 高速缓存(Cache Memory)
指CPU中的高速缓冲存储器,在2024年的今天,指的是CPU架构中的三级缓存。访问内存时,会通过总线提取数据到CPU中的Cache Memory中,随后提交给CPU核心进行处理。Cache Memory中的数据访问速度比对内存的访问快得多。
1.3 主存(Main Memory)
即平时所说的内存。它是一系列连续的字节存储位,可以通过一个个字节进行寻址。
内存地址是反向的(little-endian),指物理地址的最后一位编号最小,第一位编号最大。
如十进制的17000000,翻译为16进制为0x01036640,实际存储在内存中时是40660301,占用4个字节,第一个字节为最低位40,第二个字节为66,第三个03,第四个为最高位01。
1.4 程序在内存中的布局
一个运行中的程序所需要的数据都要放入内存中供CPU存取,而操作系统会给每个程序都分配一个独立的内存空间,在这个内存空间中的程序通常以以下的方式进行布局:
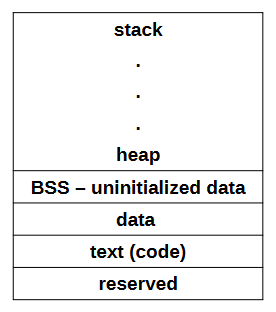
**BSS(Block Started by Symbol)**是未初始化的数据存放的位置。
Data是全局变量存放的位置。
text是存放指令的区域,通常为只读。
stack/heap是大名鼎鼎的内存堆栈区域。
1 | ⭐提出问题: |
2. 汇编入门
此部分需要提前了解一些编码知识,如原码反码补码等。还需要一些进制转换的知识。
2.1 注释
英文分号(;)注释
1 | ;注释 |
2.2 数值的写法
1 | ;默认10进制 |
2.3 定义一个常数
上面的关键字equ就是等于的意思<常数名> equ <常数值>
常数没有类型的概念,常数就是一个数值。
编译器会选择适合的大小对常数进行存储。比如10000可以存储到word或double-word大小的空间中,但是byte由于是8bits,最大只能表示到128所以不会把10000存入到byte大小的空间中。
2.4 定义一个变量(data)
<变量名> <类型> <初始值>
1 | section .data ; 表示以下存储在data区域 |
需要注意,db/dw/dd/dq分别代表了byte/word/double-word/Quadword大小的变量,并不是像高级编程语言中的类型一样的概念,这里关注的是大小。而第3行中的Hello World是一个字符串,其实是一个char列表,每一个字符各自存储于8bit的空间中。第6行中也是100,200,300三个元素存储于三个dd的空间中作为列表而存在。
2.5 声明一个未初始化的变量(BSS)
在上节对BSS(Block Started by Symbol)有简单介绍,该位置存储未初始化的变量,用以下方式声明:
<变量名> <类型> <数量>
1 | section .bss ; 表示以下存储在bss区域 |
2.6 汇编代码(text)
1 | section .text ; 表示以下存储在text区域 |
由于指令集的复杂性,汇编代码中其他部分的将放在后面学习指令集的时候继续进行。
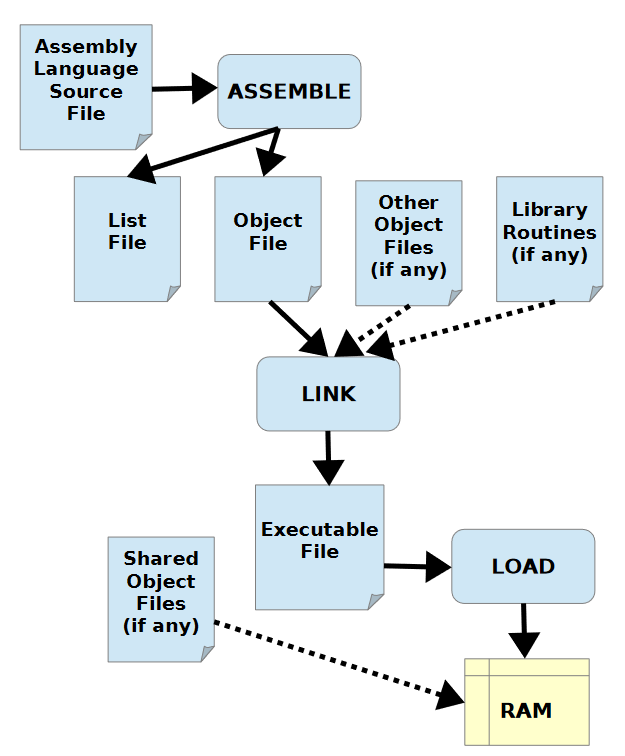
3. 工具链
把代码编译成可执行程序的过程中所需要的工具称为工具链。
对于汇编语言,工具链有多种选择,通常包括汇编器Assembler、链接器Linker、加载器Loader、调试器Debugger。
- 汇编器Assembler将人类可读的源文件转换为对象文件。
- 这些对象文件通常由链接器Linker转换成可执行文件。
- 加载器Loader将可执行文件加载到内存中。
- 调试器Debugger用于调试程序。
下图展示了Assemble->Link->Load的过程
3.1 汇编器
以一条真实的汇编器在Ubuntu下执行的命令为例:
1 | yasm -g dwarf2 -f elf64 example.asm -l example.lst |
以下解释命令的含义
yasm:一个开源汇编器,支持x86_64指令集的汇编,更多介绍参见官方网站。本文使用当前最新版1.3.0

-g dwarf2:表示选择dwarf2作为debug格式
-f elf64:表示输出对象格式为elf64
example.asm:指已经写好的汇编代码文件,yasm对它进行汇编
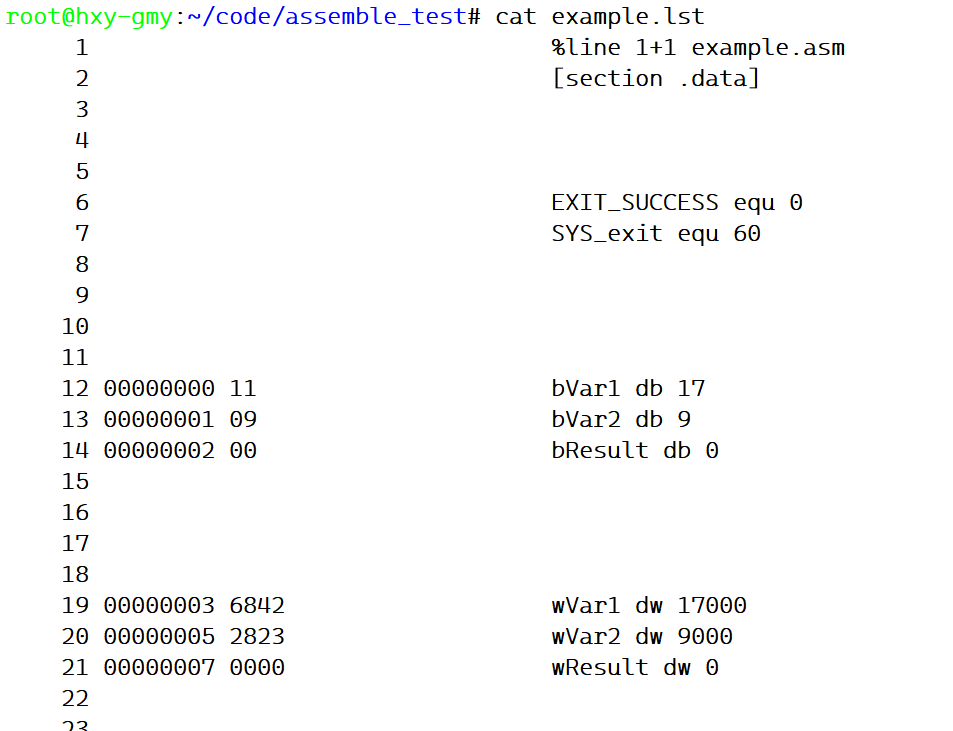
-l example.lst:指创建一个名为example.lst的列表文件方便后期调试,列表文件在上图中也出现了,它存储了汇编程序列表数据以方便查找指令,文件内容示例如下图,可以很方便地理解它是什么。
汇编的过程通常包括两步:
第一步:
创建符号表
符号表是程序中的每一个变量名、标签和符号的列表,它还包括相对地址,上图即为符号表。
解析宏(Macro)
宏可以理解为对一系列指令的封装
解析仅含常量的表达式(Constant Expression)
例如
mov rax, buff+5这条指令,如果buff是一个已经定义好的常量,在第一步中可以直接解析完成
第二步:
- 生成最终的代码
- 创建列表文件(如果需要生成的话)
- 创建对象文件(即最终的.o文件)
1
2
3
4
5
6
7
8⭐提出问题:
资料显示这里其实还有一个叫做
直接汇编指令(Assembler Directives)
的指令,这个指令被汇编器执行而不是转化为CPU指令。
那么,不转化为CPU指令是如何被汇编器执行的?
解决思路:
暂时搁置,写完这篇之后再补充学习。
3.2 链接器
同样的方式:
1 | ld -g -o example example.o |
ld:指GNU Linker,使用率很高的一个链接器,古神,GNU的LD手册居然于1998年更新。
-g:表示输出调试信息
-o example:创建一个叫做example的可执行文件
example.o:汇编器汇编好的对象文件,可以有多个,比如
ld -g -o example example.o a.o b.o
外部调用问题
在汇编生成的object file对应的列表文件中,有些调用了外部的变量或函数无法确认需要调用的地址,就会使用一个R字符来标记。
链接器会在链接的过程中对有R标记的指令进行解析,确定目标的地址。
在C/C++中,R标记类似于extern关键字,在当前文件中没有这个函数或变量,就使用extern关键字声明它在外部已经定义好了,可以通过编译。
动态链接问题
即某些符号的解析推迟到程序执行时。 实际的指令不在可执行文件中,而是在运行时根据需要进行解析和访问。即模块化了程序,可以有些通用的库拿出来等运行时再访问,这样对库的实现的优化也可以不必重新链接。缺点是库升级时如果不兼容之前的接口就会破坏程序运行,对于有些严格测试性能的程序可能很不友好。
windows中,这些库的后缀一般是dll,linux中一般为so。
3.3 加载器
加载器其实是OS的一部分,指把可执行文件从Secondary Storage(硬盘)调入Main Memory(内存)并创建新的进程、标记可执行。然后OS来决定对进程的调度。
3.4 调试器(GDB)
GDB(GNU Debugger)是一个调试工具,可以调试二进制文件、core文件、running progress,可以用DDD(一个GDB可视化前端)来熟悉GDB的使用。
工具的使用是一个熟练度的问题,在ubuntu中使用man gdb有一条很有用的学习指南,即最常使用的命令推荐:
Here are some of the most frequently needed GDB commands:
break [file:][function|line]
Set a breakpoint at function or line (in file).run [arglist]
Start your program (with arglist, if specified).bt Backtrace: display the program stack.
print expr
Display the value of an expression.c Continue running your program (after stopping, e.g. at a breakpoint).
next
Execute next program line (after stopping); step over any function calls in the line.edit [file:]function
look at the program line where it is presently stopped.list [file:]function
type the text of the program in the vicinity of where it is presently stopped.step
Execute next program line (after stopping); step into any function calls in the line.help [name]
Show information about GDB command name, or general information about using GDB.quit
exit
1 | 心得20240602: |