分析Go官方源码库总结得出的优质Go基准测试的几个准则
摘要 在 Go 语言的持续演进中,基准测试不仅是性能度量工具,更是防止性能退化的防线。在本文中我试图通过对官方源码库中基准测试的分析,了解基准测试的设计哲学,为构建领域特定 Benchmark 提供可复用的方案。
现有的多份资料中,都提到过基准测试的几条准则,如“可重复性、可观测性、可展示性、真实性、可执行性”,或者“多次迭代、结果可复现、硬件相关、需求相关 ”,比较权威的有“Relevance, Representativeness, Equity, Repeatability, Cost-effectiveness, Scalability, Transparency ”等。在概念上目前没有一个通用的说法。
作为学习者,在本文中通过对 Go 语言标准库 runtime/rwmutex_test.go 中一组读写锁(RWMutex)基准测试的实证分析,提炼出优质基准测试的两大核心准则:变量隔离性、目标相关性 ,也是我认为一个优质的基准测试两个最基本的准则。进一步地,本文归纳了基准测试应关注的四个层级:语言机制、库与工具、系统行为、实验流程。
1. 基准测试的准则 以Go源代码目录下src/runtime/rwmutex_test.go中的读写锁基准测试为例,分析一个优质的基准测试应该符合什么样的准则。
首先来看第一个基准测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func BenchmarkRWMutexUncontended (b *testing.B) type PaddedRWMutex struct { RWMutex pad [32 ]uint32 } b.RunParallel(func (pb *testing.PB) var rwm PaddedRWMutex rwm.Init() for pb.Next() { rwm.RLock() rwm.RLock() rwm.RUnlock() rwm.RUnlock() rwm.Lock() rwm.Unlock() } }) }
它的测量目标为在多核并行、无共享变量、无False Sharing (通过pad [32]uint32进行缓存行隔离)的情况下,RWMutex的基本操作开销。
在单个Goroutine中,按照顺序执行读锁->读锁->解开读锁->解开读锁->写锁->解开写锁 的操作,它作为一个对照组来控制好可能对RWMutex的操作产生影响的各种变量。经过多次执行该Benchmark,得出以下结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 hxy@ubu22:~/app/go_1.25.1/src $ go test -bench ^BenchmarkRWMutexUncontended$ -benchmem -run=^$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexUncontended-8 310858947 3.817 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.589s hxy@ubu22:~/app/go_1.25.1/src $ go test -bench ^BenchmarkRWMutexUncontended$ -benchmem -run=^$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexUncontended-8 314629580 3.864 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.612s hxy@ubu22:~/app/go_1.25.1/src $ go test -bench ^BenchmarkRWMutexUncontended$ -benchmem -run=^$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexUncontended-8 289060170 3.814 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.531s
命令执行了五次,主要输出结果为倒数第三行以及最后一行的执行时长,倒数第三行的含义为该benchmark并行度为8,执行了约3亿次迭代,平均每次迭代耗时稳定在 3.83±0.02 ns/op ,每次操作分配0内存,申请0次堆内存,其中最重要的结果应该是平均每次迭代耗时。
对结果进行对比可知,RWMutex的性能表现非常稳定,具备统计上的显著性,这个结果完全可以代表读写锁在完全无竞争的情况下,在当前的操作系统与硬件平台上的执行效率。
此结果构成了后续所有对比实验的Baseline 。
我们继续来看它如何通过控制变量来得出读写锁的性能表现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func benchmarkRWMutex (b *testing.B, localWork, writeRatio int ) var rwm RWMutex rwm.Init() b.RunParallel(func (pb *testing.PB) foo := 0 for pb.Next() { foo++ if foo%writeRatio == 0 { rwm.Lock() rwm.Unlock() } else { rwm.RLock() for i := 0 ; i != localWork; i += 1 { foo *= 2 foo /= 2 } rwm.RUnlock() } } _ = foo }) } func BenchmarkRWMutexWrite100 (b *testing.B) benchmarkRWMutex(b, 0 , 100 ) } func BenchmarkRWMutexWrite10 (b *testing.B) benchmarkRWMutex(b, 0 , 10 ) } func BenchmarkRWMutexWorkWrite100 (b *testing.B) benchmarkRWMutex(b, 100 , 100 ) } func BenchmarkRWMutexWorkWrite10 (b *testing.B) benchmarkRWMutex(b, 100 , 10 ) }
benchmarkRWMutex 为通用的控制变量用的辅助函数,它的含义是,在不同的读工作量(localwork)与不同的写操作比例(writeRatio)下RWMutex的性能表现,第2-5个函数调用benchmarkRWMutex 来分别对localwork和writeRatio进行赋值。
BenchmarkRWMutexWrite100表示每100次操作中有一次写锁
BenchmarkRWMutexWrite10表示每10次操作中有一次写锁,本地工作(读操作)不需要等待,直接加锁完了就解锁
BenchmarkRWMutexWorkWrite100表示每100次操作中有一次写锁,同时本地工作(读操作)量较大
BenchmarkRWMutexWorkWrite10表示每10次操作中有一次写锁,也有很多本地工作,模拟读写锁负载都较高的情况
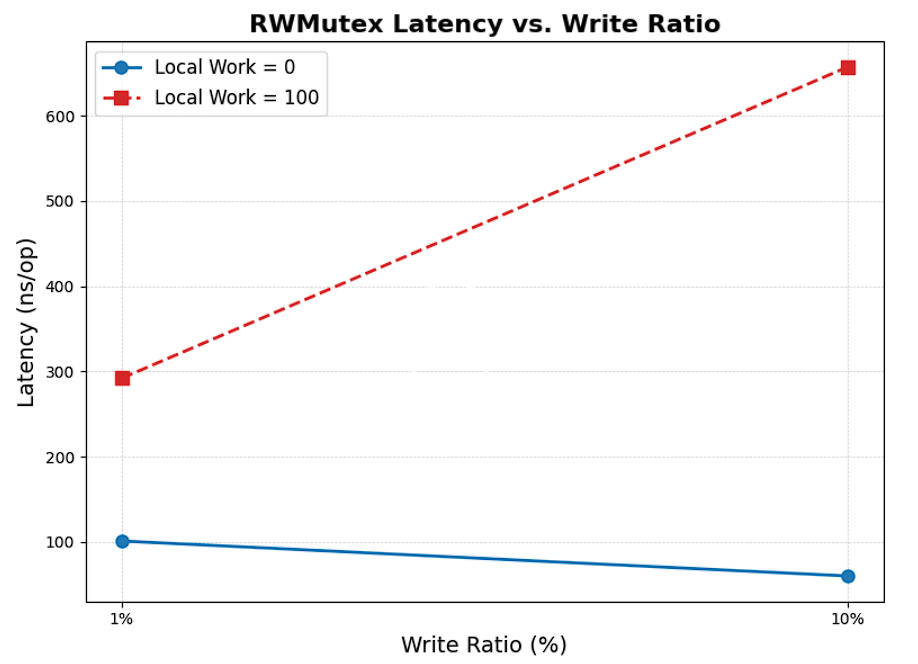
我们来看它的结果,由于结果过多,我每一个测试展示了两次执行的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWrite100$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWrite100-8 13890078 91.59 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.370s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWrite100$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWrite100-8 13798215 111.6 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.636s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWrite10$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWrite10-8 19026660 54.61 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.111s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWrite10$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWrite10-8 20960262 65.37 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.438s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWorkWrite100$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWorkWrite100-8 4638330 291.0 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.619s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWorkWrite100$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWorkWrite100-8 4723968 293.9 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.654s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWorkWrite10$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWorkWrite10-8 2020388 661.1 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.945s hxy@ubu22:~/app/go_1.25.1/src $ go test -benchmem -run=^$ -bench ^BenchmarkRWMutexWorkWrite10$ runtime goos: linux goarch: amd64 pkg: runtime cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkRWMutexWorkWrite10-8 1960510 653.8 ns/op 0 B/op 0 allocs/op PASS ok runtime 1.908s
以上实验通过对读写锁的变量控制,分析了RWMutex的执行性能,我们对其结果进行解读。
Benchmark 名称
写比例
local work
平均耗时 (ns/op)
相对非竞争放大倍数
BenchmarkRWMutexUncontended33%
极短
3.8 ns
1x(基准)
BenchmarkRWMutexWrite1001%
无
100 ns
26x
BenchmarkRWMutexWrite1010%
无
60 ns
16x
BenchmarkRWMutexWorkWrite1001%
高(100次)
292 ns
76x
BenchmarkRWMutexWorkWrite1010%
高(100次)
657 ns
172x
我们可以得出几个结论 :
锁竞争对性能影响巨大(无锁竞争情况对比有锁竞争)。
在读锁极短的场景下,适度提高写比例反而能减少写锁等待,提高整体效率(Write100 vs write10 )。
读锁较长时,一旦有写锁等待,会把读写锁都阻塞,导致后续所有锁等待。
读锁较长时,写比例越高,性能越差。
我们可以将总延迟分解为三个组成部分 :
基底开销 :约 3.8 ns,来自原子指令与轻量同步;锁争用开销 :因 Goroutine 排队、调度介入引发的状态切换;公平性代价 :长持读锁会阻塞后续写操作,而一旦写请求排队,Go 的 RWMutex 公平性策略会优先唤醒写协程,导致大量正在等待的读协程集体阻塞,为防止写饥饿,系统牺牲读吞吐所付出的成本。
所以这个结果是由于读写锁在调度器层面的资源争用导致的。
可以看到,通过对可能影响性能表现的变量的精细化控制,我们得出了一个非常精细的结论,如果没有对于变量的精细控制,我们不可能得出这样的结论。而对于测量锁性能的目标,做到这里已经达成了目标。如果继续深入探寻该结论的底层原因,那并非基准测试 要做的事,继续执行该benchmark,使用更多的配置组合,再用上梯度下降的算法等手段,也许可以找到一个最佳的读写锁比例,指导程序的编写或优化方向。
2. 基准测试的重要维度 在深入 Go 性能研究时,我们不能只盯着单个函数的 ns/op。真正的性能测试工程需要跨越多个抽象层级进行分析。
首先我们来看一下官方benchmark 中都包含哪些内容
以下是该仓库的文件目录,几个有可能产生歧义的部分含有注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 ├── build │ └── build.go // 测试 Go 编译器、链接器的性能与产物大小。 ├── cmd │ ├── bench │ └── bent // 两个命令行工具,bent通过toml配置运行的测试集和参数执行测试 ├── codereview.cfg ├── driver // 不同的环境下的驱动,适配多个操作系统 │ ├── driver_darwin.go │ ├── driver.go │ ├── driver_go10.go │ ├── driver_go12.go │ ├── driver_go15.go │ ├── driver_linux.go │ ├── driver_plan9.go │ ├── driver_stub.go │ ├── driver_unix.go │ ├── driver_wasm.go │ └── driver_windows.go ├── garbage │ ├── garbage.go // 依赖nethttp.go产生垃圾,考察GC的吞吐和暂停时间。 │ └── nethttp.go // http产生的短寿命对象,构造大对象和临时内存分配 ├── gc_latency // 产生垃圾、触发GC、测量吞吐性与延迟 │ ├── latency.go // 测量allocation latency │ ├── latency_test.go │ └── main.go ├── go.mod ├── go.sum ├── http │ └── http.go // 本地启动server和client,client反复发起请求,测量请求-响应的时延和吞吐。 ├── json │ ├── json_data.go │ └── json.go // marshal和unmarshal的速度、内存分配、不同选项的对比 ├── stats // 对结果进行统计输出的组件,处于采集完性能数据的后续位置 │ ├── edm.go │ ├── edm_test.go │ ├── edmx.go │ ├── itree.go │ └── itree_test.go ├── sweet // 服务级别的大型benchmark套件 │ ├── benchmarks │ ├── cli │ ├── cmd │ ├── common │ ├── generators │ ├── harnesses │ ├── README.md │ └── source-assets └── third_party ├── biogo-examples └── bleve-bench
总结一下官方这个benchmark套件,来看一下go语言的设计者们如何进行基准测试。
把这些基准测试按照级别进行分类,会发现它囊括了好几个层级:
Level
测试内容
举例
语言特性
GC吞吐量,GC延迟
garbage.go, gc_latency.go
标准库与工具
库函数、编译器、链接器等性能
json.go, http.go, build.go
大型服务
整体性能
sweet套件,生物信息学套件,全文检索套件
测试的基础设施
跨平台支持、标准化输出工具
driver_*.go, ./stats/
同时,在细节上来说:
基准测试需要在概念上非常严谨,即使吞吐、延迟这样的非常类似但是实际上完全不同的优化点也要完全区分
基准测试的流程需要比较完善,从不同平台的驱动,到不同级别的性能数据的采集,到数据的标准化输出
基准测试需要从多个维度贴近真实的负载,比如sweet套件中的服务、bent的配置化运行、对关键的库函数的性能分析、语言特性级别的性能分析,这样的从宏观到微观可以较为方便地进行归因。
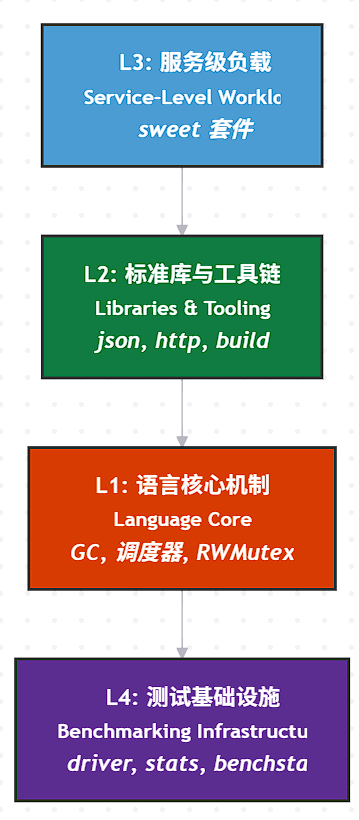
我们可以将上述维度整合为一个分层性能归因框架 :
层级
关注问题
典型指标
代表测试
L1: 语言机制
“Runtime 是否高效?”
GC 暂停、调度延迟
gc_latency, garbage
L2: 库与工具
“常用组件是否够快?”
ns/op, B/op, allocs/op
json, http, build
L3: 系统行为
“整体服务是否稳定?”
QPS, P99 延迟, 错误率
sweet 套件
L4: 实验流程
“测量是否可信?”
结果的可复现性
driver, stats
这个模型的意义在于:当发现性能问题时,可以自顶向下逐层排查 。
比如线上服务延迟升高,可以:
先看 sweet 是否复现(L3)
再检查 http 或 json 是否退化(L2)
最后验证 gc_latency 是否异常(L1)
并确保所有测试在相同 driver 环境下运行(L4)
我把它叫做四维性能观测模型 。
除此之外,这其中的每一个基准测试,包括GC吞吐量、GC延迟、json解析、http、编译工具链 等,这些内容都是非常具有代表性的性能瓶颈点,可以作为我以后关注go程序性能的参考。
这个benchmark所选的基准既有可控的微观场景也有逼近真实工作负载的宏观场景,结合完善的驱动、采集、统计分析的流程,提供了一个适合做严谨、可复现性能研究的实验平台。
3. 结论 Go 团队的 Benchmark 设计并非随意而为,而是在丰富经验指导下写出的一套优质的基准测试套件,一定程度上代表了软件工程中遇到的各种经典的、主要的问题。
Benchmark 即实验设计,每一个性能测试都应像科学实验一样
有明确的目标指引,即需要有目标相关性;
也有科学的控制变量排查方法,即变量隔离性;
也应该建立多层级观测体系,自顶向下地进行测试。
4. 下步计划 接下来的内容是一些完善的官方性能分析工具,与Benchmark互相是很好的补充。