allocs: A sampling of all past memory allocations block: Stack traces that led to blocking on synchronization primitives cmdline: The command line invocation of the current program goroutine: Stack traces of all current goroutines. Use debug=2 as a query parameter to export in the same format as an unrecovered panic. heap: A sampling of memory allocations of live objects. You can specify the gc GET parameter to run GC before taking the heap sample. mutex: Stack traces of holders of contended mutexes profile: CPU profile. You can specify the duration in the seconds GET parameter. After you get the profile file, use the go tool pprof command to investigate the profile. symbol: Maps given program counters to function names. Counters can be specified in a GET raw query or POST body, multiple counters are separated by '+'. threadcreate: Stack traces that led to the creation of new OS threads trace: A trace of execution of the current program. You can specify the duration in the seconds GET parameter. After you get the trace file, use the go tool trace command to investigate the trace.
在中间部分
1 2 3 4 5 6 7 8 9 10 11 12 13
Types of profiles available: Count Profile 6 allocs 0 block 0 cmdline 5 goroutine 6 heap 0 mutex 0 profile 0 symbol 11 threadcreate 0 trace full goroutine stack dump
(pprof) help Commands: callgrind Outputs a graph in callgrind format comments Output all profile comments disasm Output assembly listings annotated with samples dot Outputs a graph in DOT format eog Visualize graph through eog evince Visualize graph through evince gif Outputs a graph image in GIF format gv Visualize graph through gv kcachegrind Visualize report in KCachegrind list Output annotated source for functions matching regexp pdf Outputs a graph in PDF format peek Output callers/callees of functions matching regexp png Outputs a graph image in PNG format proto Outputs the profile in compressed protobuf format ps Outputs a graph in PS format raw Outputs a text representation of the raw profile svg Outputs a graph in SVG format tags Outputs all tags in the profile text Outputs top entries in text form top Outputs top entries in text form topproto Outputs top entries in compressed protobuf format traces Outputs all profile samples in text form tree Outputs a text rendering of call graph web Visualize graph through web browser weblist Display annotated source in a web browser o/options List options and their current values q/quit/exit/^D Exit pprof
Options: call_tree Create a context-sensitive call tree compact_labels Show minimal headers divide_by Ratio to divide all samples before visualization drop_negative Ignore negative differences edgefraction Hide edges below <f>*total focus Restricts to samples going through a node matching regexp hide Skips nodes matching regexp ignore Skips paths going through any nodes matching regexp intel_syntax Show assembly in Intel syntax mean Average sample value over first value (count) nodecount Max number of nodes to show nodefraction Hide nodes below <f>*total noinlines Ignore inlines. normalize Scales profile based on the base profile. output Output filename for file-based outputs prune_from Drops any functions below the matched frame. relative_percentages Show percentages relative to focused subgraph sample_index Sample value to report (0-based index or name) show Only show nodes matching regexp show_from Drops functions above the highest matched frame. showcolumns Show column numbers at the source code line level. source_path Search path for source files tagfocus Restricts to samples with tags in range or matched by regexp taghide Skip tags matching this regexp tagignore Discard samples with tags in range or matched by regexp tagleaf Adds pseudo stack frames for labels key/value pairs at the callstack leaf. tagroot Adds pseudo stack frames for labels key/value pairs at the callstack root. tagshow Only consider tags matching this regexp trim Honor nodefraction/edgefraction/nodecount defaults trim_path Path to trim from source paths before search unit Measurement units to display
Option groups (only set one per group): granularity functions Aggregate at the function level. filefunctions Aggregate at the function level. files Aggregate at the file level. lines Aggregate at the source code line level. addresses Aggregate at the address level. sort cum Sort entries based on cumulative weight flat Sort entries based on own weight : Clear focus/ignore/hide/tagfocus/tagignore
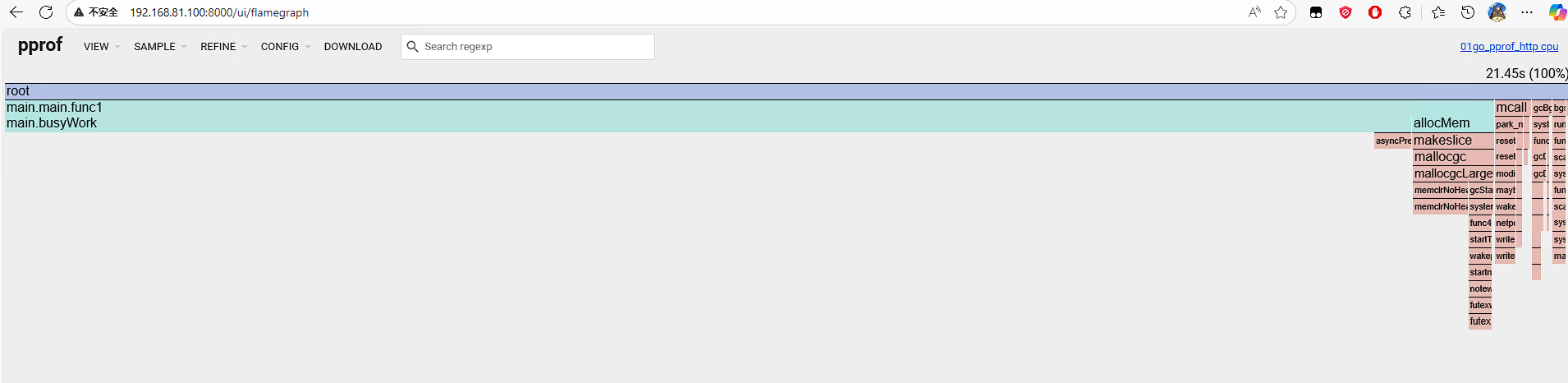
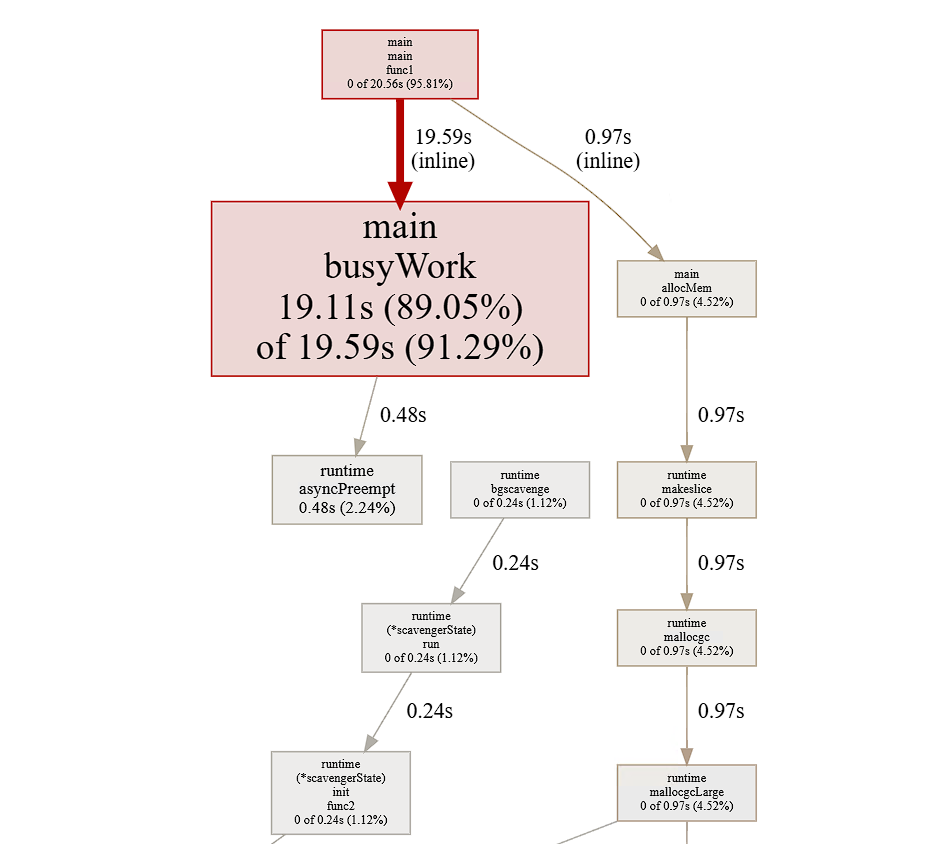
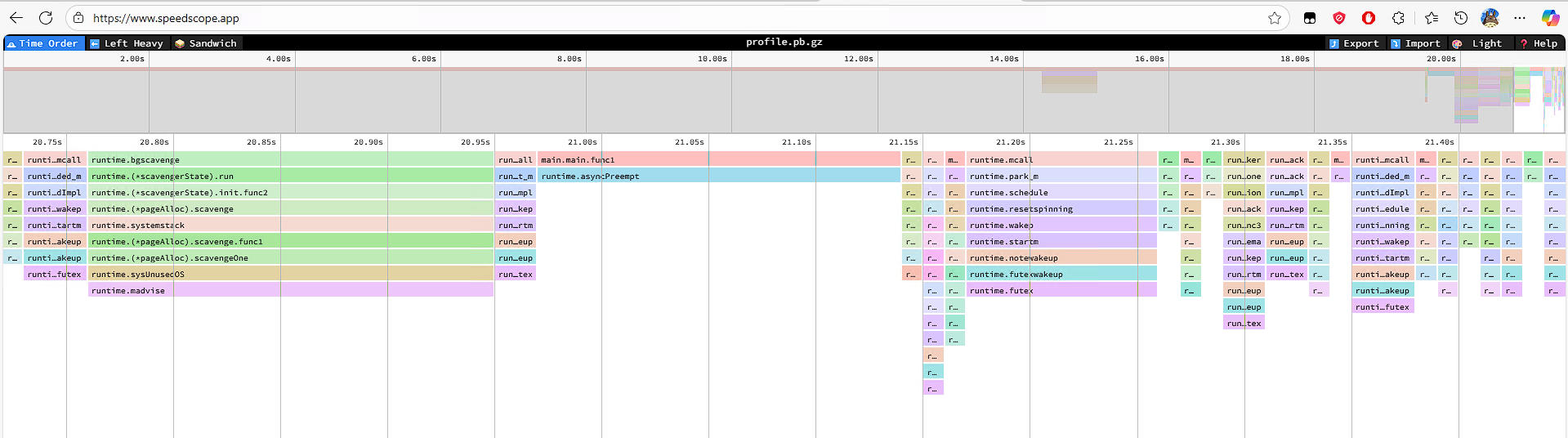
$ go tool pprof -http=0.0.0.0:8000 http://127.0.0.1:6060/debug/pprof/profile Fetching profile over HTTP from http://127.0.0.1:6060/debug/pprof/profile Saved profile in /home/hxy/pprof/pprof.01go_pprof_http.samples.cpu.003.pb.gz Serving web UI on http://0.0.0.0:8000 Couldn't find a suitable web browser!
Set the BROWSER environment variable to your desired browser.