Go perf 使用记录
1. 介绍 Go perf在 官方介绍 中的定义为 Go benchmark analysis tools ,即一个 Go benchmark 分析工具合集。它包含用于分析基准测试结果数据的命令行工具。
非常全面,涵盖了从格式化解析、分组、过滤、统计学分析、结果发布等一站式全流程的工具,再次发扬分类技能:
取数据(benchstat、benchunit、benchfmt)->
数据清洗(benchstat、benchfilter、benchproc、benchmath)->
结果发布 (benchsave)
看起来非常专业且全面。
接下来使用一个测试用例对其全流程试用。
2. 使用 2.1 编写基准测试 该基准测试测试了不同方式拼接字符串。
stringconcat.go 用了四种不同的字符串拼接方式
1 2 3 4 5 6 7 8 9 10 11 12 func concatWithPlus (n int , s string ) string {}func concatWithBuilder (n int , s string ) string {}func concatWithBuffer (n int , s string ) string {}func concatWithJoin (n int , s string ) string {}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func BenchmarkConcatPlus100 (b *testing.B) func BenchmarkConcatPlus1000 (b *testing.B) func BenchmarkConcatBuilder100 (b *testing.B) func BenchmarkConcatBuilder1000 (b *testing.B) func BenchmarkConcatBuffer100 (b *testing.B) func BenchmarkConcatBuffer1000 (b *testing.B) func BenchmarkConcatJoin100 (b *testing.B) func BenchmarkConcatJoin1000 (b *testing.B)
2.2 执行测试,保存到文件 我们先试用一下:
benchmark1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 hxy@ubu22:~/app/go/04benchstat $ go test -bench=. -benchmem perf goos: linux goarch: amd64 pkg: perf cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkConcatPlus100-8 17325 68958 ns/op 387027 B/op 99 allocs/op BenchmarkConcatPlus1000-8 147 8414351 ns/op 38739436 B/op 1001 allocs/op BenchmarkConcatBuilder100-8 154357 8133 ns/op 34992 B/op 12 allocs/op BenchmarkConcatBuilder1000-8 18228 68162 ns/op 286130 B/op 19 allocs/op BenchmarkConcatBuffer100-8 154564 7525 ns/op 29616 B/op 9 allocs/op BenchmarkConcatBuffer1000-8 19663 60497 ns/op 264369 B/op 12 allocs/op BenchmarkConcatJoin100-8 390640 2972 ns/op 9984 B/op 2 allocs/op BenchmarkConcatJoin1000-8 52074 22966 ns/op 90112 B/op 2 allocs/op PASS ok perf 12.821s
以BenchmarkConcatPlus100-8的数据为例解释一下数据的含义:
17325:指被采纳作为统计结果的函数执行次数
hxy注:这里有个坑,因为这个次数和我规定的次数不同,经查阅资料,Go有一些机制 保证统计的内容是足够稳定的结果 。这个”一些机制”目前还并没有查到非常详细的解释。
68958 ns/op :每次操作消耗的时间为68958次
387027 B/op :每次操作占用的内存为387027B
99 allocs/op:每次操作申请内存的次数为99次
没有什么问题,保存到文件
1 go test -bench=. -benchmem perf > results.txt
benchfilter1 benchfilter pkg:perf results.txt > filtered.txt
结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 goos: linux goarch: amd64 pkg: perf cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics BenchmarkConcatPlus100-8 16501 68975 ns/op 387027 B/op 99 allocs/op BenchmarkConcatPlus1000-8 169 7.939114e+06 ns/op 3.8739447e+07 B/op 1002 allocs/op BenchmarkConcatBuilder100-8 157008 8399 ns/op 34992 B/op 12 allocs/op BenchmarkConcatBuilder1000-8 18838 56281 ns/op 286130 B/op 19 allocs/op BenchmarkConcatBuffer100-8 172484 6617 ns/op 29616 B/op 9 allocs/op BenchmarkConcatBuffer1000-8 22144 66326 ns/op 264369 B/op 12 allocs/op BenchmarkConcatJoin100-8 393951 2982 ns/op 9984 B/op 2 allocs/op BenchmarkConcatJoin1000-8 52179 26365 ns/op 90112 B/op 2 allocs/op
benchstat
1 benchstat filtered.txt > stat.txt
结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 goos: linux goarch: amd64 pkg: perf cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics │ filtered.txt │ │ sec/op │ ConcatPlus100-8 68.98µ ± ∞ ¹ ConcatPlus1000-8 7.939m ± ∞ ¹ ConcatBuilder100-8 8.399µ ± ∞ ¹ ConcatBuilder1000-8 56.28µ ± ∞ ¹ ConcatBuffer100-8 6.617µ ± ∞ ¹ ConcatBuffer1000-8 66.33µ ± ∞ ¹ ConcatJoin100-8 2.982µ ± ∞ ¹ ConcatJoin1000-8 26.37µ ± ∞ ¹ geomean 41.58µ ¹ need >= 6 samples for confidence interval at level 0.95 │ filtered.txt │ │ B/op │ ConcatPlus100-8 378.0Ki ± ∞ ¹ ConcatPlus1000-8 36.94Mi ± ∞ ¹ ConcatBuilder100-8 34.17Ki ± ∞ ¹ ConcatBuilder1000-8 279.4Ki ± ∞ ¹ ConcatBuffer100-8 28.92Ki ± ∞ ¹ ConcatBuffer1000-8 258.2Ki ± ∞ ¹ ConcatJoin100-8 9.750Ki ± ∞ ¹ ConcatJoin1000-8 88.00Ki ± ∞ ¹ geomean 174.9Ki ¹ need >= 6 samples for confidence interval at level 0.95 │ filtered.txt │ │ allocs/op │ ConcatPlus100-8 99.00 ± ∞ ¹ ConcatPlus1000-8 1.002k ± ∞ ¹ ConcatBuilder100-8 12.00 ± ∞ ¹ ConcatBuilder1000-8 19.00 ± ∞ ¹ ConcatBuffer100-8 9.000 ± ∞ ¹ ConcatBuffer1000-8 12.00 ± ∞ ¹ ConcatJoin100-8 2.000 ± ∞ ¹ ConcatJoin1000-8 2.000 ± ∞ ¹ geomean 17.73 ¹ need >= 6 samples for confidence interval at level 0.95
2.3 结果解析 stat.txt结果有三个维度
378.0ki 指的就是每次操作分配了378KiB内存。
99.00 指每次操作分配了99次内存
我们把置信区间也搞出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 以下是之前的命令使用流程 go test -bench=. -benchmem perf > results.txt benchfilter pkg:perf results.txt > filtered.txt benchstat filtered.txt > stat.txt # 以下是一个shell脚本,多次实验 for i in {1..10}; do go test -bench=. -benchmem perf > ./out/result.$i.txt done cat ./out/result.*.txt > ./out/all_results.txt benchfilter pkg:perf ./out/all_results.txt > ./out/all_filtered.txt benchstat ./out/all_filtered.txt > ./out/all_stat.txt
结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 goos: linux goarch: amd64 pkg: perf cpu: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics │ ./out/all_filtered.txt │ │ sec/op │ ConcatPlus100-8 72.91µ ± 7% ConcatPlus1000-8 7.416m ± 9% ConcatBuilder100-8 7.628µ ± 9% ConcatBuilder1000-8 60.46µ ± 3% ConcatBuffer100-8 6.976µ ± 7% ConcatBuffer1000-8 56.42µ ± 3% ConcatJoin100-8 3.262µ ± 8% ConcatJoin1000-8 25.65µ ± 5% geomean 41.14µ │ ./out/all_filtered.txt │ │ B/op │ ConcatPlus100-8 378.0Ki ± 0% ConcatPlus1000-8 36.94Mi ± 0% ConcatBuilder100-8 34.17Ki ± 0% ConcatBuilder1000-8 279.4Ki ± 0% ConcatBuffer100-8 28.92Ki ± 0% ConcatBuffer1000-8 258.2Ki ± 0% ConcatJoin100-8 9.750Ki ± 0% ConcatJoin1000-8 88.00Ki ± 0% geomean 174.9Ki │ ./out/all_filtered.txt │ │ allocs/op │ ConcatPlus100-8 99.00 ± 0% ConcatPlus1000-8 1.002k ± 0% ConcatBuilder100-8 12.00 ± 0% ConcatBuilder1000-8 19.00 ± 0% ConcatBuffer100-8 9.000 ± 0% ConcatBuffer1000-8 12.00 ± 0% ConcatJoin100-8 2.000 ± 0% ConcatJoin1000-8 2.000 ± 0% geomean 17.73
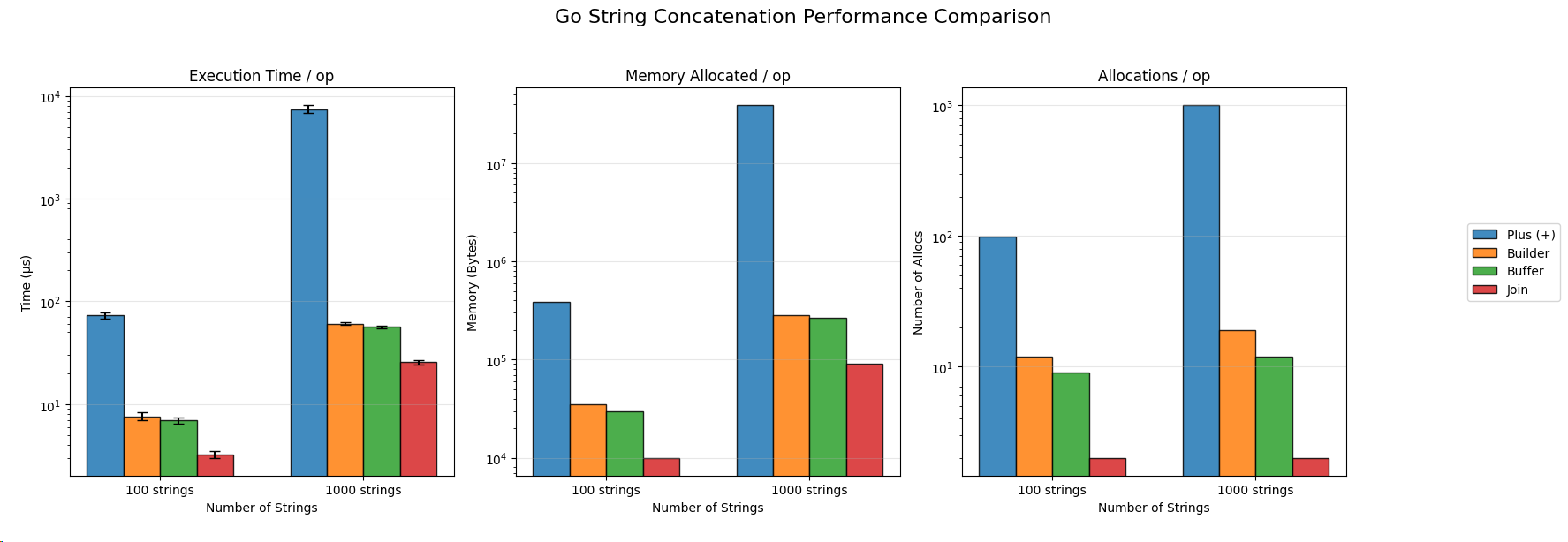
经过对比,不同的String拼接的性能对比如下:
我们可以看出:
strings.Join最快、最省内存、最少分配 += 的方式性能较差:性能差、内存爆炸、GC 压力大 strings.Builder / bytes.Buffer所有方法在 N=1000 时性能差距更明显,说明问题随规模放大
3. 总结 经过以上内容,我们理解了一套使用benchstat的流程,这一套流程可以对benchmark的结果进行专业的对比分析全流程。对以程序员的角度 理解程序非常有帮助。
这个流程本质上是取数据 -> 数据清洗 -> 可视化展示 的过程
通过go test -bench -benchmem的方式获取性能数据。
通过benchfilter 和benchstat 对数据进行一定的整理。
拿到结果数据之后对数据进行可视化展示,本文的可视化展示是通过 python + numpy + matplotlib 来实现的,通过对图例和维度的调整可以清晰地展示结果。
这套流程的主要优点是,它给了一套通用的性能测试方法论,以及一套非常科学的统计维度和计算方式。从方法论上来讲,取数据 -> 数据清洗 -> 可视化展示 这个大方向的流程非常科学。从统计维度上来讲,这套工具是由一群来自谷歌的非常有经验的性能测试工程师给出的非常典型的,包含平均执行时间、内存占用、内存申请次数的统计维度,这些维度精准地代表了程序的性能表现。而从计算方式来讲,它告诉了我们应该对拿到的数据选取什么样的计算方式,比如运行多次取平均值,仅取稳定的数据,多次试验取几何平均值,多次实验得到置信区间等。
hxy注:这套流程的主要缺点我认为也很明显,
数据清洗的过程有些简单,仅包含一些简单的filter,也许是我还没有测试更多的包,但大概率还是使用python自写脚本进行数据处理更加自由和定制化。
虽然维度选择非常经典,但是有时候就是会需要更加全面的测试维度。
我们取其精华即可。
4. 下步计划 继续完善工具学习试用计划。
使用TMA脚本,以系统的视角 来继续理解性能测试与优化。