1. 介绍
Top-down Micro-architecture Analysis Methodology(TMAM,自顶向下的微架构分析方法)。这是 Intel CPU 工程师归纳总结用于优化CPU性能的方法论。TMAM 理论基础就是将各类 CPU 各类微指令进行归类从大的方面先确认可能出现的瓶颈,再进一步下钻分析找到瓶颈点,该方法也符合我们人类的思维,从宏观再到细节,过早的关注细节,往往需要花费更多的时间。这套方法论的优势在于:
- 即使没有硬件相关的知识也能够基于CPU的特性优化程序。
- 系统性的消除我们对程序性能瓶颈的猜测。
- 快速的识别出在多核乱序CPU中瓶颈点。
以上介绍出自Intel官方文档的翻译。
这一套方法提出了一个对性能瓶颈进行分层归因的理论,在论文中主要分为4层,在实际工程中分为了6层,根据不同微架构的CPU可能不太相同。
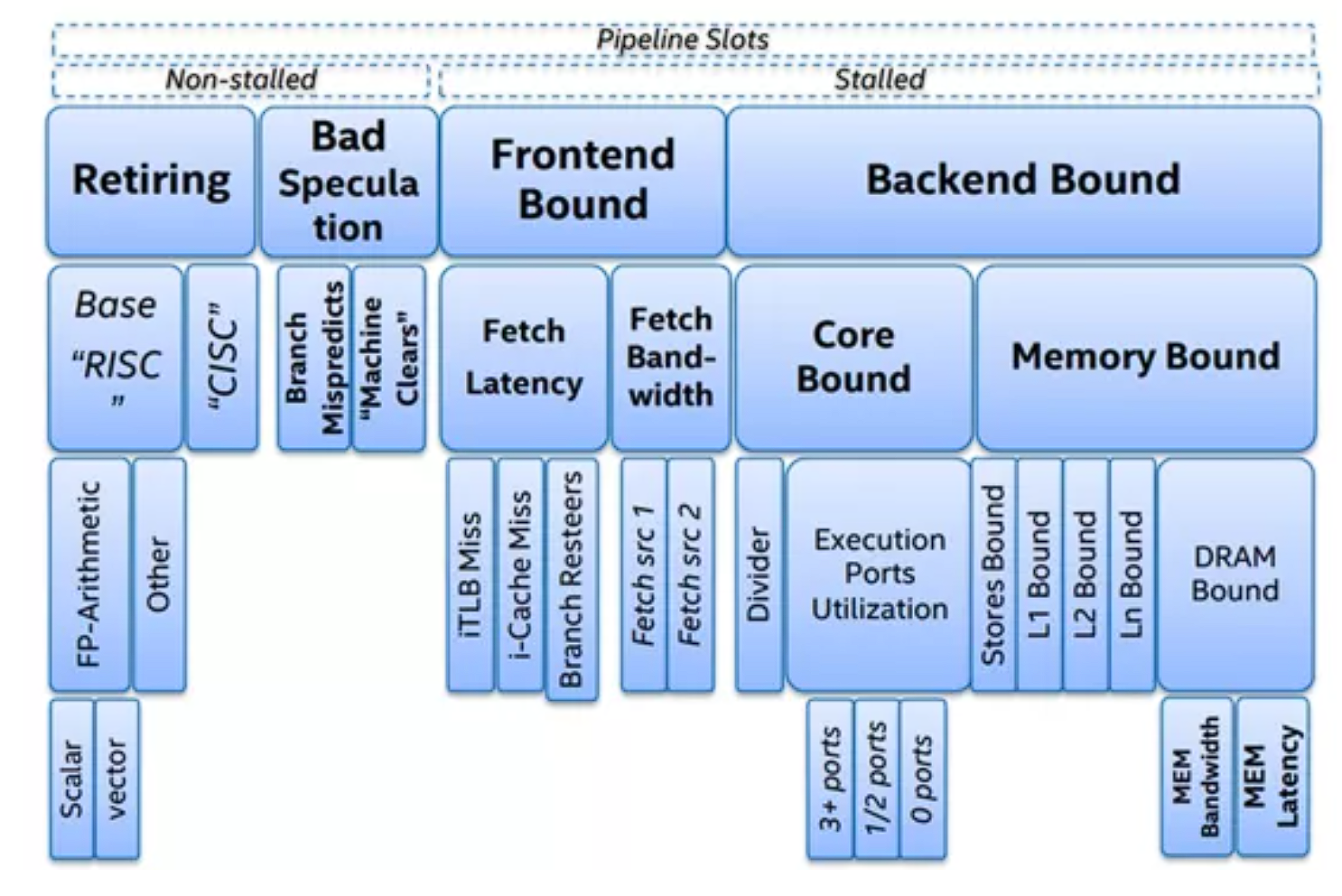
上图展示了论文中4层归因架构,最上面的Retiring, Bad Speculation, Frontend Bound, Backend Bound这四个 uOps 的状态是第一层,在实际工程中表示为TopdownL1,它用来查找性能瓶颈主要在哪个状态下。
接下来三层都是如此。
接下来,我将通过具体使用这套方法来进行解释它的工作原理。
2. 具体使用
测试平台:
OS: Ubuntu22.04.1 6.8.0-85-generic x86_64
CPU: Intel(R) Core(TM) i5-3337U CPU @ 1.80GHz , 2 Cores 4 Threads
Total online memory: 3.9GiB
perf version 6.8.12
1 | 开放性能采集的权限: |
2.1 TopdownL1
1 | perf stat -a -M TopdownL1 -- sleep 60 |
在perf stat -a -M TopdownL1 -- sleep 60这条命令中,-a表示全局行为,而不是只采集sleep 60的行为。
perf 基于底层硬件计数器计算出了四个 Top-Down 类别的周期占用比例:
| 瓶颈类别 | 占比 | 含义 |
|---|---|---|
| tma_frontend_bound | 56.7% | 前端无法供给足够 uop |
| tma_backend_bound | 25.6% | 后端执行资源受限或内存延迟高 |
| tma_retiring | 12.4% | 只有少量时间在做“有用工作” |
| tma_bad_speculation | 5.3% | 推测错误导致浪费,尚属正常范围 |
这是一个典型的低利用率 + 前端受限场景。
我们来看它是怎么算出来的。
采集事件的含义:
CPU_CLK_UNHALTED.THREAD_ANY表示在所有未停机的CPU周期中,监视的线程所在物理核心在运行的周期CPU_CLK_UNHALTED.THREAD表示在所有未停机的CPU周期中,监视的线程在运行的CPU周期数CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE表示在所有未停机的CPU周期中,监视的线程未停机且另一个LCPU停机的晶振时钟周期数CPU_CLK_UNHALTED.REF_XCLK表示在所有未停机的CPU周期中,晶振时钟周期的数量UOPS_RETIRED.RETIRE_SLOTS表示成功退休的 uop 的 slot 数。每个 slot 最多可退休 4 个 uopIDQ_UOPS_NOT_DELIVERED.CORE表示在后端没有任务时,已经发射的uops没有经过前端传递给后端的uops数量UOPS_ISSUED.ANY表示成功发射的 uop 总数INT_MISC.RECOVERY_CYCLES_ANY表示因分支预测错误触发核弹清空(NUKE)而导致流水线恢复所花的周期,ANY表示物理核心和逻辑核心的区别IDQ.MS_UOPS表示来自微码序列器Microcode Sequencer所有的UOPS。这个定义在官方文档中是错误的,并在IceBridge和Skylake文档中得到了修正
以下解释出自 Intel 官方文档:
IDQ.MS_UOPS : Increment each cycle # of uops delivered to IDQ from MS by either DSB or MITE. Set Cmask = 1 to count cycles.
hxy note: 这个定义是错误的!在后面的IceBridge架构文档中Intel对其进行了修正。
CPU_CLK_UNHALTED.REF_XCLK : Counts core crystal clock cycles when the thread is unhalted.
CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE:Count XClk pulses when this thread is unhalted and the other thread is halted.
CPU_CLK_UNHALTED.THREAD : Core cycles when the thread is not in halt state.
CPU_CLK_UNHALTED.THREAD_ANY : Core cycles when at least one thread on the physical core is not in halt state.
IDQ_UOPS_NOT_DELIVERED.CORE : Count issue pipeline slots where no uop was delivered from the front end to the back end when there is no back-end stall.
UOPS_ISSUED.ANY : Increments each cycle the # of Uops issued by the RAT to RS. Set Cmask = 1, Inv = 1, Any= 1to count stalled cycles of this core.
INT_MISC.RECOVERY_CYCLES : Number of cycles waiting for the checkpoints in Resource Allocation Table (RAT) to be recovered after Nuke due to all other cases except JEClear (e.g. whenever a ucode assist is needed like SSE exception, memory disambiguation, etc.)
INT_MISC.RECOVERY_CYCLES_ANY : Core cycles the allocator was stalled due to recovery from earlier clear event for any thread running on the physical core (e.g. misprediction or memory nuke).
具体计算方法:
官方公式我在理解时遇到了一些歧义:
1 | metric expr 1 - (tma_frontend_bound + tma_bad_speculation + tma_retiring) for tma_backend_bound |
我用latex写了一个比较方便阅读的公式:

下面按照计算的顺序对这个公式进行更加详细的分析。
1. 计算tma_retiring
UOPS_RETIRED.RETIRE_SLOTS指正常执行完成的微指令,该事件可以被PMU采集。在当今的CPU设计中,一个 CPU 周期中包含4个slots,这个 PMU 事件指的是正常执行完成的UOPS的slot的个数。
tma_info_thread_slots指的是总流水线槽位,即在采集过程中一共有多少有效的slot。这两个的比值就是正常执行完成的微指令。
总流水线槽位指4倍物理核心活跃周期数,4这个系数对应的就是一个CPU cycle中包含4个slot。
物理核心活跃周期数的取值取决于工程师的在全局统计方面的需求和超线程的开启情况。全局统计指当SMT开启时监控采集线程所在CPU物理核心的执行情况,非全局统计指的是监控指定的程序所在的逻辑核心的执行情况。超线程开启情况就是字面意思。当core_wide = 0且开启超线程时,需要采集的PMU事件有CPU_CLK_UNHALTED.THREAD,CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE,CPU_CLK_UNHALTED.REF_XCLK,这个公式其实经过一些简单的化简。它的含义是,这个程序所在的逻辑核所在的物理核心周期中有一些是该程序独占物理核,有一些是和另一个程序共享物理核,而CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE / CPU_CLK_UNHALTED.REF_XCLK指的是通过晶振时钟来找到独享物理核的时间占运行总时间的比例,然后通过化简就得到了这个公式。
2. 计算tma_frontend_bound
计算前端没有对通过IDQ把uops发射给后端的slots数量,除以总流水线槽位即可。
3. 计算tma_bad_speculation
已经发射的uops,减去正常执行完成的uops,即为分支预测失败的的uops数量。因为分支预测失败,会触发NUKE机制,意思就是核爆掉slots,工程师的硬核起名法,然后重新塞入slot,这个过程需要时间。再加上这个时间内所占的槽位,就是分支预测失败所占全部槽位。除以总槽位得到tma_bad_speculation。
4. 计算tma_backend_bound
1减去以上所有即可。
计算方法的总结
在我们要对Micro-architecture进行分析的时候,按照自顶向下的方法是一套比较科学的方案,它按照以下层次进行划分
2.2 TopdownL2
1 | hxy@hxy-gmy:~ |
在TMA的L2中,从论文来看其实不太需要把第二层所需要的维度全都进行,只需要把L1中的瓶颈对应的L2进行Profiling即可,但是perf的TopdownL2依然把所有的维度的性能数据都进行计算了。
L2的瓶颈类别如下:
| L1 | tma_frontend_bound | tma_backend_bound | tma_bad_speculation | tma_retiring |
|---|---|---|---|---|
| L2 | tma_fetch_latency | tma_memory_bound | tma_branch_mispredicts | tma_heavy_operations |
| tma_fetch_bandwidth | tma_core_bound | tma_machine_clears | tma_light_operations |
采集事件的含义:
IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOPS_DELIV.CORE:没有任何一个uops被IDQ传递给后端的CPU周期数BR_MISP_RETIRED.ALL_BRANCHES:所有被成功执行的但是分支预测错误了的指令,该指令会触发NUKE使流水线槽清空MACHINE_CLEARS.COUNT:表示不是因为分支预测失败,但是流水线槽被清空了的次数。内存歧义、代码自我修改等情况都可能导致该问题CYCLE_ACTIVITY.STALLS_LDM_PENDING:因为等待加载数据而停顿的CPU周期,即读内存停顿CYCLE_ACTIVITY.CYCLES_NO_EXECUTE:没有执行uop的CPU周期RESOURCE_STALLS.SB:因为存储缓冲区(SB, Store Buffer)满了而导致的后端资源停顿CPU周期数CYCLE_ACTIVITY.CYCLES_NO_EXECUTE:没有任何UOPS执行的CPU周期数UOPS_EXECUTED.CYCLES_GE_1_UOP_EXEC:至少有1个UOP被执行的CPU周期数UOPS_EXECUTED.CYCLES_GE_2_UOPS_EXEC:至少有2个UOPS被执行的CPU周期数UOPS_EXECUTED.CYCLES_GE_3_UOPS_EXEC:至少有3个UOPS被执行的CPU周期数RS_EVENTS.EMPTY_CYCLES:保留站Reservation Station为空的周期,它表示后端此时无法从RS接收UOPSINST_RETIRED.ANY:已执行完成的指令
以下解释出自 Intel 官方文档:
IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOPS_DELIV.CORE: Cycles per thread when 4 or more uops are not delivered to Resource Allocation Table (RAT) when backend of the machine is not stalled.
BR_MISP_RETIRED.ALL_BRANCHES: Mispredicted branch instructions at retirement.
MACHINE_CLEARS.COUNT: Number of machine clears (nukes) of any type.
CYCLE_ACTIVITY.STALLS_LDM_PENDING: Execution stalls due to memory subsystem.
CYCLE_ACTIVITY.CYCLES_NO_EXECUTE: Total execution stalls.
RESOURCE_STALLS.SB: Cycles stalled due to no store buffers available (not including draining form sync).
UOPS_EXECUTED.CYCLES_GE_1_UOP_EXEC: Cycles where at least 1 uop was executed per-thread.
UOPS_EXECUTED.CYCLES_GE_2_UOPS_EXEC: Cycles where at least 2 uops were executed per-thread.
UOPS_EXECUTED.CYCLES_GE_3_UOPS_EXEC: Cycles where at least 3 uops were executed per-thread.
RS_EVENTS.EMPTY_CYCLES: Cycles the RS is empty for the thread.
INST_RETIRED.ANY: Instructions retired from execution.
具体计算方法:

下面按照计算的顺序对这个公式进行更加详细的分析。
tma_fetch_latency指的是取指延迟,它被定义为“没有任何一个uops被传递给后端的CPU周期数”和“总CPU周期数”的比值。而min机制是作为一个安全钳而存在的,防止当虚拟机、计数器溢出等异常情况出现时算出110%取指溢出这种结果。tma_fetch_bandwidth指取指带宽不够,它的含义是前端问题要么是取指延迟要么是取指带宽的问题。带宽问题指一个CPU周期中传递给后端的UOPS不足4个,即因为带宽问题前端没有充分取指。tma_bad_speculation的算法是分支预测次数占(分支预测次数 + 其它原因导致NUKE)的比例tma_machine_clears指的是其它原因导致NUKE的占比tma_heavy_operations的含义就十分明显了,它计算的是正常完成的SLOTS总数占总发射的UOPS数量的比例,乘以来自微码序列器MS的UOPS数量与总槽位的比例,即为正常完成的、且来自微码序列器的UOPS占总槽位的比例。tma_light_operations = tma_retiring - tma_heavy_operationstma_memory_bound本质上是内存停顿周期和总后端执行停顿周期的比值,这个式子是我自己加的中间变量以方便理解,下面分别解释一下内存停顿周期和总后端执行停顿周期。内存停顿周期 (Cycles_Memory_Stall) 的计算公式简单直接,就是读内存停顿周期加上写内存停顿周期
总后端执行停顿周期 (Cycles_Execution_Stall) 这个公式十分地复杂,继续拆解它为四个部分,即为我在公式中通过换行使其变为四行,每一行为一个部分
第一行指的是后端执行的总CPU周期数,定义为没有任何UOPS被执行的CPU周期 + 至少有一个UOP被执行的CPU周期。
第二行指的是后端执行较好的CPU周期数量。分类进行了讨论,分类标准是IPC的阈值1.8,超过1.8表示后端执行的很好,此时我们把每个CPU周期内执行大于等于3个UOPS算是后端执行较好的CPU周期,当小于等于1.8时,把每个CPU周期内执行大于等于2个UOPS的周期算是后端执行较好的周期。
第三行指的是非后端问题导致后端无法执行的问题数量。同样进行了分类讨论,当前端的取指延迟小于等于0.1时就直接把问题全归为后端,否则就减去保留站为空的周期数。
第四行指的是读内存停顿周期。即因为后端来不及从Store Buffer读取指令导致停顿的CPU周期数。
这样就得到了:
总后端停顿周期 = 后端执行的总CPU周期数 - 后端执行较好的CPU周期数量 - 非后端问题导致后端无法执行的问题数量 + 读内存停顿周期
所以:
tma_memory_bound = 内存停顿周期 / 总后端执行停顿周期 * tma_backend_bound
tma_core_bound = tma_backend_bound - tma_memory_bound
总结
TopdownL1计算方法解析
version 1
- 计算
tma_info_thread_slots即总流水线槽位,通常它指的是(4 * CPUcycles),即4倍CPU周期,这是因为现代CPU的流水线结构一般都是4级流水线,即4个stage,每个stage的宽度为1,因此一个CPU周期内可以处理4个微指令。总流水线槽位作为分母,用于计算各个指标的权重。在细节上,CPUcycles的计算方式是根据采集的目标分类讨论的,可以由CPU_CLK_UNHALTED.THREAD,CPU_CLK_UNHALTED.ONE_THREAD_ACTIVE,CPU_CLK_UNHALTED.REF_XCLK这些PMU EVENT进行计算得到,具体见上方分析。 - 计算
tma_retiring,即正常执行完成的流水线槽位占总流水线槽位的比例。正常执行完成的流水线槽位可以由UOPS_RETIRED.RETIRE_SLOTS这个PMU EVENT进行采集得到。 - 计算
tma_frontend_bound,前端性能不足,即前端没有及时把足够的UOPS交给后端的流水线槽位所占比例。可以由IDQ_UOPS_NOT_DELIVERED.CYCLE.CORE这个PMU EVENT进行计算得到。 - 计算
tma_bad_speculation,即前端交付给后端错误的UOPS的比例。可以由UOP的发射数 - 正常执行完成的UOP数 + 恢复slot状态的UOPS数量进行计算得到。这三个指标都有对应的PMU EVENT,具体可以查看上方分析。 - 计算
tma_backend_bound,后端性能不足,可以由以上状态的比例进行计算得到。
version 2
- 获取执行时间内的总流水线槽位作为以下计算的分母。
- 获取正常执行完成的UOPS数量,得到所占比例。
- 获取前端没有及时交付UOPS的比例。
- 获取前端交付错误的UOPS的比例。
- 剩余的SLOTS就是后端的性能不足所占的比例。
TopdownL2计算方法解析
对L2计算流程的解析难度比L1高很多。
Perf 关于 TopdownL2 的计算没有基于L1的结果,它默认计算所有L2维度。在实际使用中,并不需要计算所有L2的维度,只需要计算经过L1计算出的异常指标的L2子指标即可,在后续没有Topdown方法的计算时,可以注意这一点。
version 1
- 计算
tma_info_thread_slots即总流水线槽位,通常它指的是(4 * CPUcycles)作为分母 - 查看L1的计算结果,看有哪些异常指标。
case bad L1:
when tma_frontend_bound:step 3;
when tma_bad_speculation:step 4;
when tma_retiring:step 5;
when tma_backend_bound:step 6;break;
default:happy ending - 计算
tma_fetch_latency, tma_fetch_bandwidth,即发生取指延迟的周期和取指带宽不足的周期。取指延迟可以由IDQ_UOPS_NOT_DELIVERED.CYCLES_0_UOPS_DELIV.CORE这个PMU EVENT进行计算得到,具体见上方分析。其余则为前端本身取指带宽的问题,导致没有传输足够的UOPS。 - 计算
tma_branch_mispredicts, tma_machine_clears,这个分支预测错误之后的UOP不会被执行,除此之外,还有已经执行但是执行错误的UOP共同组成错误预测这个L1指标。这个指标可以由BR_MISP_RETIRED.ALL_BRANCHES, MACHINE_CLEARS.COUNT这两个PMU EVENT进行计算得到。 - 计算
tma_heavy_operations, tma_light_operations,heavy指的是通过微码序列器传递的指令,light指的是通过DSB和MITE传递的小于等于4UOPS的指令。 - 计算
tma_memory_bound, tma_core_bound,即后端内存问题和后端计算问题。主要计算后端内存问题。内存问题可以由读写内存停顿占用总执行停顿的比例进行计算。而总执行停顿的计算是由后端总CPU周期-后端正常执行完成的CPU周期-前端没有传入UOP的周期+后端写数据写不出去导致的CPU停顿周期。
version 2
- 获取执行时间内的总流水线槽位
- 查找异常L1指标
- 通过前端未传递UOPS的比例计算L2的取指延迟和带宽延迟问题比例
- 通过分支预测失败的UOP和SLOT清空的UOP计算L2的分支预测错误和机器清零的问题比例
- 通过计算经由MS发布的UOP数量计算heavy和light指令的比例
- 通过计算后端读写内存停顿所占的比例计算L2的后端内存问题和计算问题比例
心得
经过一系列艰苦的查资料和理解,总算是搞定了TopdownL1和L2的详细计算方法。
其实看下来没有特别难的计算公式,只是这些公式像是绣花活一样非常地精细。有了这个公式,可以参考TMA的思想对其他的架构进行计算。
另外还有一个问题,若要真正理解这个公式,也许还需要一步通过自己的理解把它讲清楚,并且还需要把能讲清楚的时间压缩一下。
下步计划
DCPerf : benchmark suite for hyperscale cloud applications的上手和理解。